|
Yu-Ying Yeh I am a Research Scientist at Meta Reality Lab. I earned my Ph.D. from UC San Diego, working with Prof. Manmohan Chandraker. I am fortunate to intern at Adobe Research, NVIDIA Research, and Meta Reality Lab during my Ph.D. study. Before joining UCSD, I was a research assistant working with Prof. Yu-Chiang Frank Wang at National Taiwan University. My research interest focuses on computer vision and graphics, with applications related to photorealistic 3D content creation, inverse rendering, and neural rendering. I'm honored to receive the Google PhD Fellowship and be a finalist for the Meta PhD Research Fellowship and Qualcomm Innovative Fellowship. Email / CV / Google Scholar / Github |

|
ResearchMy research interest mainly focuses on the intersection of computer vision and computer graphics, including but not limited to inverse rendering, 3D reconstruction, material and lighting estimation for indoor scene, object, and portrait. My goal is to enable photorealistic content creation automatically for AR/VR applications. |

|
TextureDreamer: Image-guided Texture Synthesis through Geometry-aware Diffusion
Yu-Ying Yeh, Jia-Bin Huang, Changil Kim, Lei Xiao, Thu Nguyen-Phuoc, Numair Khan, Cheng Zhang, Manmohan Chandraker, Carl S Marshall, Zhao Dong, Zhengqin Li CVPR, 2024 project page / arxiv / data TextureDreamer transfers photorealistic, high-fidelity, and geometry-aware textures from 3-5 images to arbitrary 3D meshes. |

|
Learning to Relight Portrait Images via a Virtual Light Stage and Synthetic-to-Real Adaptation
Yu-Ying Yeh, Koki Nagano, Sameh Khamis, Jan Kautz, Ming-Yu Liu, Ting-Chun Wang SIGGRAPH Asia, 2022 project page / arxiv / video We propose a single-image portrait relighting method trained with our rendered dataset and synthetic-to-real adaptation to achieve high photorealism without using light stage data. Our method can also handle eyeglasses and support video relighting. |

|
PhotoScene: Photorealistic Material and Lighting Transfer for Indoor Scenes
Yu-Ying Yeh, Zhengqin Li, Yannick Hold-Geoffroy, Rui Zhu, Zexiang Xu, Miloš Hašan, Kalyan Sunkavalli, Manmohan Chandraker CVPR, 2022 project page / arXiv / cvpr paper / code Transfer high-quality procedural materials and lightings from images to reconstructed indoor scene 3D geometry, which enables photorealistic 3D content creation for digital twins. |

|
OpenRooms: An Open Framework for Photorealistic Indoor Scene Datasets
Zhengqin Li, Ting-Wei Yu, Shen Sang, Sarah Wang, Meng Song, Yuhan Liu, Yu-Ying Yeh, Rui Zhu, Nitesh Gundavarapu, Jia Shi, Sai Bi, Zexiang Xu, Hong-Xing Yu, Kalyan Sunkavalli, Miloš Hašan, Ravi Ramamoorthi, Manmohan Chandraker CVPR, 2021 (Oral Presentation) project page / arXiv An open framework which creates a large-scale photorealistic indoor scene dataset OpenRooms from a publicly available video scans dataset ScanNet. |

|
Through the Looking Glass: Neural 3D Reconstruction of Transparent Shapes
Yu-Ying Yeh*, Zhengqin Li*, Manmohan Chandraker (*equal contributions) CVPR, 2020 (Oral Presentation) project page / arXiv / code / dataset / real data Transparent shape reconstruction from multiple images captured from a mobile phone. |
|
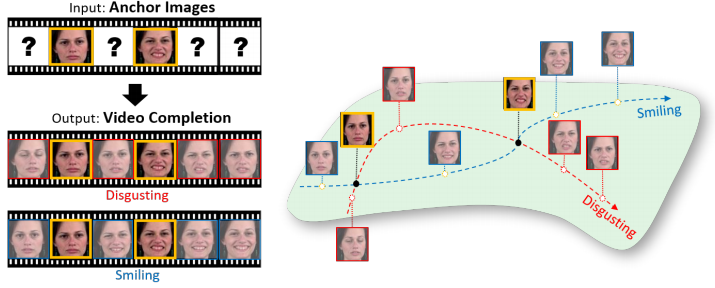
Static2Dynamic: Video Inference from a Deep Glimpse
Yu-Ying Yeh, Yen-Cheng Liu, Wei-Chen Chiu, Yu-Chiang Frank Wang IEEE Transactions on Emerging Topics in Computational Intelligence, 2020 paper / bibtex Video generation, interpolation, inpainting and prediction given a set of anchor frames. |
|
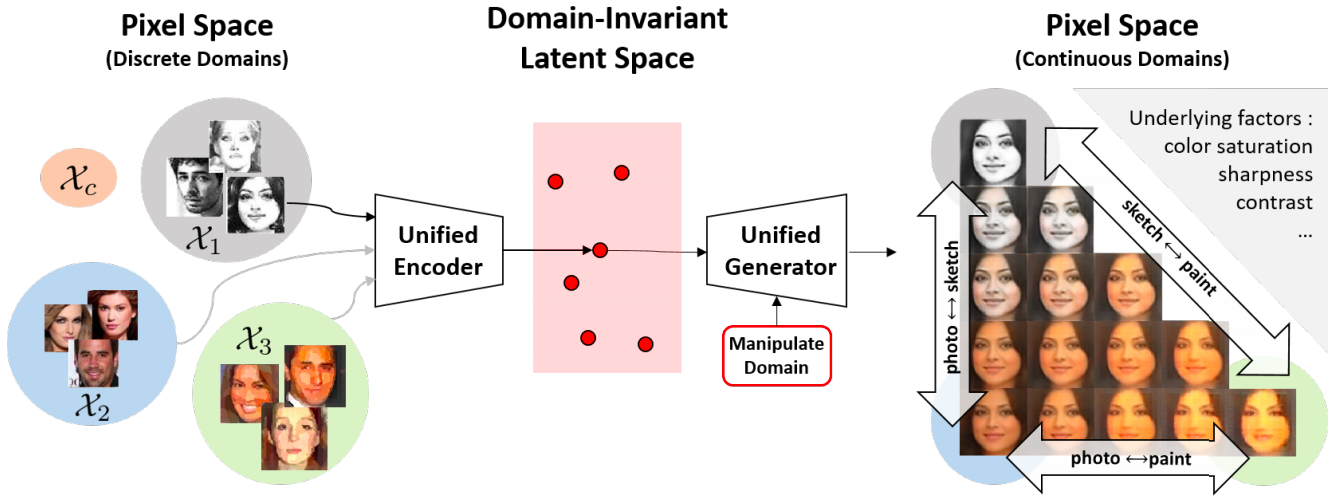
A Unified Feature Disentangler for Multi-Domain Image Translation and Manipulation
Alexendar Liu, Yen-Cheng Liu, Yu-Ying Yeh, Yu-Chiang Frank Wang NeurIPS, 2018 arXiv / bibtex / code A novel and unified deep learning framework which is capable of learning domain-invariant representation from data across multiple domains. |
|
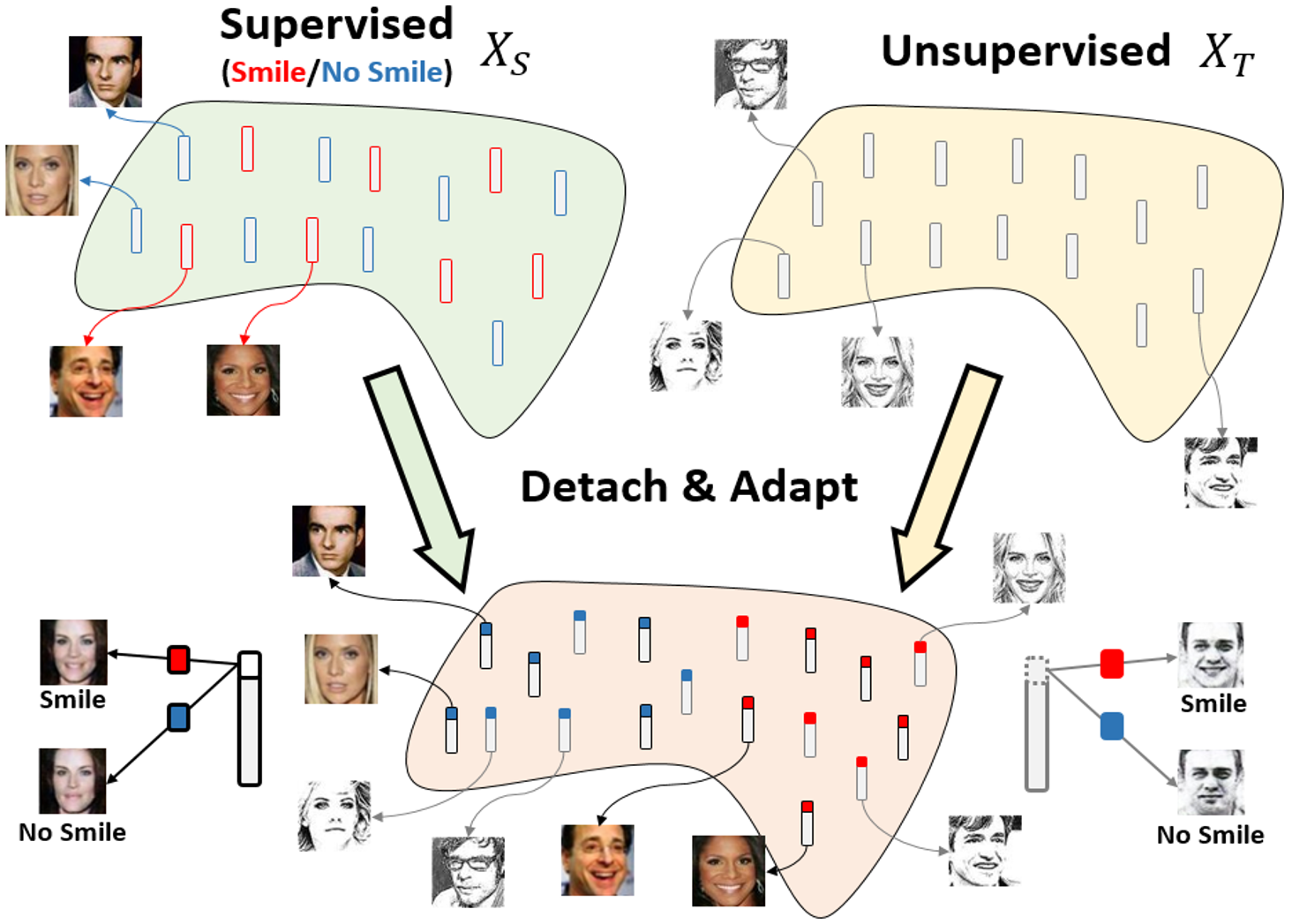
Detach and Adapt: Learning Cross-Domain Disentangled Deep Representation
Yen-Cheng Liu, Yu-Ying Yeh, Tzu-Chien Fu, Wei-Chen Chiu, Sheng-De Wang, Yu-Chiang Frank Wang CVPR, 2018 (Spotlight Presentation) paper / bibtex / code / presentation Feature disentanglement for cross-domain data which enables image translation and manipulation from labeled source doamin to unlabeled target domain. |
Miscellanea |
|
Reviewer:
ICCV ’19, AAAI ’20, CVPR ’20, ECCV ’20, NeurIPS ’20, ICLR ’21,
CVPR ’21, ICCV’21, NeurIPS’21, CVPR’22, ECCV’22, NeurIPS'22, Computer Graphics Forum
|
|
|
Teaching Assistant: Intro to Computer Vision: CSE152A WI22, CSE152A SP19, CSE152A WI19 Advanced Computer Vision: CSE252D SP21 Domain Adaptation in Computer Vision: CSE291A00 WI20 Honors and Awards: 2022 Meta PhD Research Fellowship Finalist 2022 Qualcomm Innovative Fellowship Finalist 2022 Google PhD Fellowship Recipient [CSE News] |
|
This page is adapted from this template which is created by Jon Barron.
|
